본 게시물은 Joung and Kim (2021)이 개발한 방법의 핵심이 되는 부분만 정리하였습니다. 관심 있는 분들은 원문을 확인하시는 게 가장 정확합니다!
Joung, J., & Kim, H. M. (2021). Explainable neural network-based approach to Kano categorisation of product features from online reviews. International Journal of Production Research, 1–21. https://doi.org/10.1080/00207543.2021.2000656
Back Ground
Kano Model
Kano 모델은 제품이나 서비스가 가진 구성 요소가 소비자의 전반적 만족도에 미치는 방식을 바탕으로 분류합니다. 즉, 완제품의 부분에 속하는 구성 요소가 개별적으로 어떤 방식으로 소비자를 만족시키는지를 보여줍니다. Wiki 백과사전에서 가져온 그림으로 설명하자면, 아래와 같이 구분할 수 있는데요. X축은 구성 요소의 품질 수준을 의미하고, Y 축은 소비자가 전반적으로 만족하는 수준을 의미합니다.

예를 들어보자면, Performance 요소는 품질 수준이 향상될수록 소비자의 만족도가 상승하는 특징을 가지며, 품질 수준이 떨어지는만큼 소비자의 만족도가 하락합니다. 자동차를 완제품으로 둔다면 엔진의 출력 수준이 대표적인 performance 요소라고 할 수 있습니다. 한편, Basic 요소는 품질 수준이 만족스럽지 않다면 소비자 만족도가 하락하지만, 품질 수준이 만족스럽더라도 소비자의 만족도는 증가하지 않습니다. 이를 당위 요소 (must-be)라고 해석하는 경우가 많은데 여기서는 Basic이라고 했네요. 이 요소의 예시로는 안전벨트의 안정성이 대표적입니다. 우리가 차를 고를 때, 안전벨트가 제대로 작동하지 않으면 당연히 구매하지 않겠지만, 안전벨트가 엄청나게 좋은 품질이라고 해도 딱히 차량 구매에 큰 영향은 미치지 않습니다.
Kano categorization
Kano categorization은 제품의 구성 요소를 분류하는 과정을 의미합니다. 위의 예시에서 엔진이나 안전벨트는 상당히 해당 구성 요소가 어떤 요소인지 직관적으로 알 수 있지만, 그렇지 않은 구성 요소도 있습니다. 예컨대, 차량의 사이드 미러는 어떤 요소에 속할까요? 크면 클수록 고객의 만족도가 증가할지 작아도 만족도가 감소하지 않을지 직관적으로 예상하기 어렵습니다.
이렇게까지 구성 요소를 분류하는 이유는 구성 요소의 분류에 따라 차기 제품에서 어떻게 이를 개선할지 아이디에이션을 할 수 있기 때문입니다. 예를 들어, 안전벨트의 성능이 이미 괜찮은 수준이면 굳이 비싼 돈과 시간을 들여 더 좋은 안전벨트를 만들 필요는 없겠지요. 안전한 안전벨트가 더욱 더 안전한 안전벨트가 된다고 하더라도 고객의 만족도가 증가하진 않으니까요. 반면 이렇게 아낀 자원을 엔진 출력에 투자한다면 고객의 만족도는 증가할 것입니다.
설문 기반의 Kano categorization
이러한 Kano categorization은 제품 개발에서 꽤나 중요하기 때문에 많은 제조, 서비스 기업에서는 구성 요소를 kano categorize하기 위해 많은 노력을 기울입니다. "Kano categorization을 한다"라고 명시적으로 표현하지 않더라도, "안전벨트 더 안전하게 할 필요 없지 않을까?"라는 논의가 이루어졌다면, 묵시적으로 kano category에 대한 논의가 이루어지고 있다고 볼 수 있습니다.
Kano categorization은 결국 고객의 만족도와 구성 요소 간의 관계를 의미하기 때문에 고객의 의견을 수용하여 수행해야 합니다. 고객의 목소리를 가장 직접적으로 들을 수 있는 방법은 직접 고객에게 찾아가서 질문해보는 것이죠. 그렇기에 전통적으로는 설문 기반의 kano categorization 많이 이루어져 왔습니다. 그런데 이런 설문 기반의 방법은 여러 가지 문제점이 있습니다. 대표적인 한계점은 아래 두 가지입니다.
- 고객을 찾아가서 질문하는 과정은 시간과 비용이 많이 듭니다 (Lee and Huang 2009)
- 설문으로부터 양질의 데이터를 축적하는 것은 매우 어렵습니다 (Groves 2006)
Kano categorization을 위해서 설문을 하는 고객의 입장이 되어 보겠습니다. "귀하는 엔진의 품질이 좋아지면 차량에 대한 만족도가 증가합니까?" "귀하는 엔진의 품질이 나빠지면 차량에 대한 만족도가 감소합니까?"라는 질문에 대해서 제대로 답변하기는 어렵습니다. 그날의 컨디션에 따라서 답변이 달라질 수 있고, 아예 엔진의 품질과 차량의 만족도를 직접적으로 연결 지어 생각하는 게 어려울 수도 있습니다. 물론 이렇게 직접적으로 물어보지는 않지만, 간접적으로 돌린 질문에 대한 답변을 kano model과 연결 짓는 것도 상당히 어려운 일입니다.
사용자 리뷰 기반의 Kano modeling
그래서 최근에는 사용자의 리뷰를 분석해서 Kano modeling을 하는 연구가 수행되어 왔습니다. 구체적으로, 사용자가 적은 리뷰와 사용자가 부여한 별점 (혹은 점수) 와의 관계를 분석해서 kano categorization을 수행하는데요. 아주 간결한 예시로 들자면 소나타에 대한 두 사용자의 리뷰가 있다고 가정해보겠습니다.
사용자 1: "NF 소나타의 엔진 출력은 이 가격대에서는 최고의 품질을 가졌습니다" (★★★★★)
사용자 2: "뽑기 운이 안 좋아서 출력이 90% 밖에 안돼서 최악이었어요" (☆)
아무래도 사용자 1은 뽑기운이 좋아서 고품질의 엔진을 받은 것 같고, 사용자 2는 저품질의 엔진을 받은 것 같네요. 엔진 출력의 차이에 따라서 사용자의 별점이 큰 차이가 났습니다. 이제 우리는 엔진 출력이라는 구성 요소는 품질이 좋을수록 사용자의 만족도를 높이고, 품질이 안 좋으면 품질을 사용자의 만족도를 낮추는 요소라는 것을 알 수 있습니다. 이거 위에서 본 Performance 요소와 같은 특징이죠?
사용자 리뷰 기반의 Kano modeling을 위에서 리뷰와 별점을 비교하는 것을 자동화하는 것을 의미합니다. 그러기 위해서는 반드시 수행돼야 하는 과업이 몇 가지 있습니다.
- 사용자 리뷰 문장 안에서 구성 요소가 무엇인지 알아야 합니다.
- 구성 요소에 대해서 사용자의 평가가 긍정적인지 부정적인지 알아야 합니다.
- 구성 요소에 대한 긍정/부정 평가가 만족도 (별점)에 미치는 효과를 알아야 합니다.
간단하게 말해서 사용자 2의 리뷰에서 관련된 구성 요소인 "출력"을 뽑아내고, "최악이었어요"라는 부정 평가를 뽑아낸 후에, 출력에 대한 부정적인 평가가 0.5 점 별점을 준다는 것을 알아내야 합니다. 생각만 해도 어렵네요.
결코 쉽지 않은 사용자 리뷰 기반 Kano categorization
그런데 사용자 3이 이런 리뷰를 달았다고 생각해보겠습니다.
사용자 3: "소나타의 엔진 출력은 최고지만 디자인이 너무 구려서 최악이에요" (☆)
사용자 1은 엔진 출력이 좋다고 5점을 줬는데, 사용자 3은 엔진 출력이 좋은데도 0.5 점을 주었습니다. 알고 보니 엔진 출력은 그렇게 중요하지 않았던 걸까요? 그게 아니라 엔진 출력은 중요한 요소인데 디자인이 정말로 최악이에서 이렇게 된 것일까요?
이때 사용자 4가 나타나서 이런 리뷰를 달았다고 생각해볼게요.
사용자 4: "소나타의 엔진 출력은 최고지만, 디자인이 너무 구림. 근데 솔직히 연비 생각하면 최고의 차지" (★★★★★)
사용자 3의 의견에 연비라는 구성 요소 하나 들어가니까 다시 5점이 되어버렸습니다. 그러면 사실 알고 보니 디자인은 그렇게 중요한 요소가 아니었던 걸까요?
정답은 각각의 구성 요소의 효과가 복잡하게 얽혀서 사용자의 최종 만족도에 영향을 미친다입니다. 조금 다른 주제일 수도 있지만 강동원 선생님이 부장님 개그를 하면 매력적일까요 아닐까요? 저는 전자라고 생각합니다. 개그 실력이라는 요소가 부정적이라도 외모가 탁월하기 때문에 전반적 매력이 높게 평가된 사례가 되었다고 할 수 있죠. Kano model도 마찬가지입니다. 여러 구성 요소가 주는 효과가 중첩되어서 최종 별점에 반영되기 마련입니다.
이제 Back ground의 거의 끝입니다. 아까 나온 강동원 선생님 사례로 돌아와서, 만약에 제가 아재 개그를 하면 어떨까요? 글쎄요... 저의 외모는 아재 개그를 이길 정도는 아닐 것 같습니다. 압도적으로 잘생긴 사람만이 아재 개그를 이기고 매력적인 사람이라고 불릴 수 있다면, 외모라는 요소보다는 개그 실력이 매력에 더 중요한 요소일 것입니다. 제품의 구성 요소도 마찬가지일 것입니다. 모든 요소들이 동일하게 제품의 전반적 만족도에 영향을 미치는 게 아닙니다. 어떤 요소는 더 크게 영향을 미치고, 어떤 요소들은 영향을 거의 안 미칠 수 있습니다.
사용자 리뷰 기반의 Kano categorization
이번에 리뷰한 논문에서는 위에서 궁금해했던 모든 것들을 "자동화하여", "정확하게", 그리고 "해석 가능하게" 분석하는 방법을 제안하였습니다. 논문에서 사용한 핵심적인 절차는 아래와 같습니다.
- Word2Vec 알고리즘을 통해 유사한 명사들을 군집화하여 제품의 구성 요소에 해당하는 단어 도출
- 구성 요소가 포함된 문장의 긍정/부정적 감성 단어 도출 후 그 수준을 평가
- f(구성 요소 1의 긍정 평가 수준, 구성 요소 1의 부정 평가 수준, 구성 요소 2의 긍정 평가 수준, 구성 요소 2의 부정 평가 수준,.....)=별점 에 해당하는 인공 신경망 학습을 통해 각 구성 요소에 대한 긍정/부정 평가가 별점에 미치는 효과 모델링
- 인공 신경망에 대한 SHAP value 도출을 통해 각 요소가 별점에 미치는 요인의 크기의 정량화
- 각 구성요소의 긍정 평가 수준의 SHAP value, 부정 평가 수준의 SHAP value를 바탕으로 Kano categorization
사용된 알고리즘에 대해서는 대략적으로 설명드리겠지만, 세부적인 알고리즘은 아래 링크를 참조하세요!
Word2Vec: https://wikidocs.net/22660
SHAP value: https://christophm.github.io/interpretable-ml-book/shap.html
Word2Vec 알고리즘을 통해 구성 요소 도출
다시 리뷰 데이터로 돌아와서, 어떤 사람은 "자동차의 디자인이 예뻐서 너무 좋아요"라고 평가할 수 있고, "자동차가 외관이 예뻐서 너무 좋아요" 라고 평가할 수 있습니다. 만약에 정직하게 있는 그대로 분석한다면, 디자인에 대한 부분을 따로 분석하고 외관에 대한 부분을 따로 분석할 것입니다. 그런데, 결국 외관은 디자인이잖아요? 그렇기 때문에 이런 동일한 의미를 가진 단어들은 하나로 묶어서 분석하는 것이 적절합니다. 같은 의미를 가진 단어를 묶게 되면, 그와 관련한 평가도 묶어서 볼 수 있으니 분석 결과의 신뢰도도 높아지겠죠.
이 논문을 이를 위해 Word2Vec이라는 알고리즘을 활용합니다. Word2Vec은 같은 문장 안에서 빈번하게 함께 활용되는 단어들에 비슷한 numerical vector를 부여하는 알고리즘입니다. 위의 예시에서는 외관에는 (1,1,1)이라는 좌표를 주고, 디자인이라는 단어에는 이와 가까운 (1.12, 1.1, 0.9) vector를 준다고 할 수 있습니다.
외관이라는 단어랑 디자인이라는 단어가 같이 쓰이지도 않았는데 왜 유사한 값을 가지냐?라고 생각하신다면 "나와 가까이 있는 사람과 가까이 있는 사람은 나와 가까이 있다"라는 개념으로 생각하시면 마음이 편해지실 겁니다. 외관, 디자인이라는 단어 모두 "예쁘다"라는 단어랑 자주 빈번하게 쓰일 것입니다. "예쁘다"라는 단어랑 가까운 단어 외관은, "예쁘다"와 가까운 단어 디자인과도 가깝겠죠.
이렇게 Word2Vec을 활용하여 단어를 vectorization 하면, vector 공간에서 가까운 단어들을 군집화할 수 있습니다.
구성 요소에 대한 긍정/부정 평가 도출
이후에는 도출된 구성 요소가 사용된 문장에서 감성 평가를 도출해야 합니다. "자동차의 디자인이 예뻐서 너무 좋아요"라고 한다면, 디자인 구성 요소에 대한 감성 평가는 "예쁘다"가 될 것입니다. 예쁘다는 대체로 긍정적인 평가이기 때문에 이 문장은 디자인 요소에 대해 긍정적인 평가를 했다고 알 수 있습니다.
대단한 분석 방법이 활용될 것 같지만, 사실 여기서는 Word bank를 활용하는 방법밖에 없습니다. Word bank에서는 각각의 단어의 감성의 수준이 정리되어 있는데요. 예컨대, "예쁘다"는 긍정 1.45점, "못생겼다"는 부정 3점 이런 식으로 정리되어 있습니다. 결국 구성 요소가 포함된 문장에서의 감성 평가가 있는 단어를 찾아내고, 그것의 점수를 word bank에서 대조하는 방식을 활용합니다.
구성 요소의 긍정/부정 평가와 별점과의 관계 분석
이제 리뷰 안에 각각의 구성 요소에 대한 긍정/부정 평가에 대한 수준이 별점에 미치는 효과를 분석해야 합니다. 이때 우리가 좋아하는 그거 쓰는 겁니다! 인공지능! 인공신경망의 디자인은 상황에 맞추어서 적당히 하면 되고, Input과 Output의 구조는 아래와 같습니다. 결국 각 구성 요소에 대해서 긍정 (부정) 평가가 있는지, 있다면 어느 정도 수준인지를 점수로 가지는 Input vector를 넣어주면 별점이 어떻게 되는지 예측하는 모델을 fitting 하는 것입니다.
SHAP value 기반의 Kano categorization
SHAP에 대한 개념은 간단하게 설명하기엔 너무 어렵습니다. 대신 이 모형에서 SHAP value가 가진 의미를 대략적으로만 설명하겠습니다. SHAP value는 fitting 된 model에 대해서 (위의 인공 신경망 모델) 각 변수들이 예측값에 미치는 영향이 어느 수준인지 알려주는 지표입니다. 예를 들자면 사용자 5가 다음과 같이 리뷰를 했다고 가정하면
사용자 5: "자동차의 외관이 최악이었어요. 연비는 최고 수준이었습니다. 엔진 출력도 좋아요" ★★★
아래와 같은 해석 결과를 제공합니다.
전체 사용자의 평균 별점은 2점이었다. 사용자 5는 외관에 대한 강한 부정 평가가 별점 -5, 연비에 대한 강한 긍정 평가가 +3, 엔진 출력에 대한 약한 긍정 평가가 +3 이었다. 통합하면, 2-5+3+3 = 3 점이고, 이게 사용자 5가 준 별점이다.
그런데 이런 해석 결과는 우리가 Kano categorization에 꼭 필요한 정보와 매우 흡사합니다.
외관에 대한 강한 부정평가가 별점 -5 ==> 외관 요소의 품질이 하락하면 전반적 만족도가 하락한다.
연비에 대한 강한 긍정 평가가 +3 ==> 연비 요소의 품질이 향상하면 전반적 만족도가 증가한다.
엔진 출력에 대한 약한 긍정 평가가 +3 이었다 ==> 엔진 출력 요소의 품질이 향상하면 전반적 만족도가 증가한다.
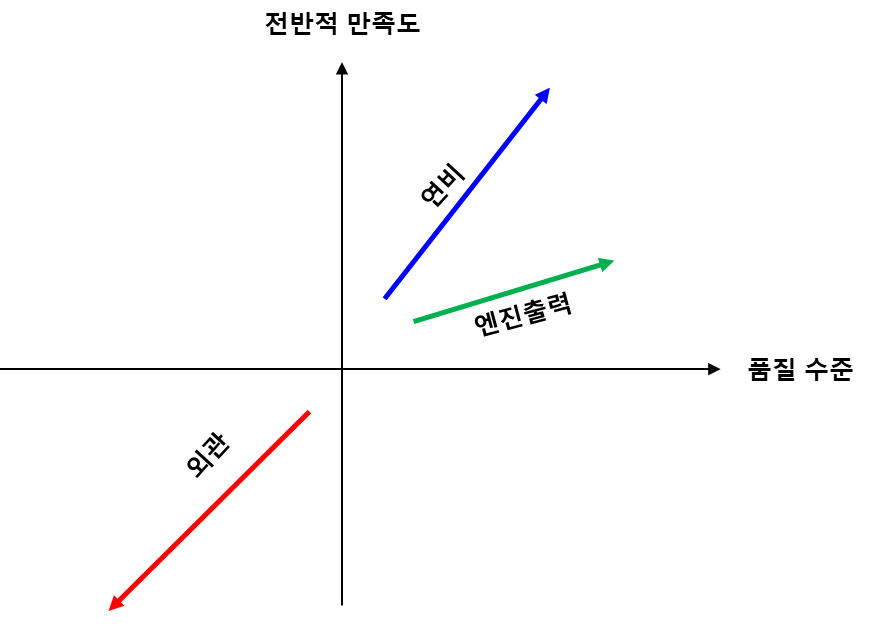
다시 Kano categorization의 그래프에 매핑하면 아래와 같습니다. 즉, 이제 연비에 대한 부정평가가 전반적 만족도에 미치는 수준, 엔진 출력의 부정 평가가 만족도에 미치는 수준, 외관의 긍정 평가가 미치는 수준만 찾아내면 각 구성 요소를 Kano categorization 할 수 있는 것입니다. 우리가 기억해야 할 것은 리뷰 데이터는 그 수가 매우 많기 때문에 각 구성 요소에 대한 평가를 찾기가 어렵지 않다는 것입니다.
마치며
오늘은 갑작스럽게 Harrison 교수님의 논문을 리뷰했습니다. 논문에서는 Fitbit에 대해서 사례연구를 하셨는데, 아무래도 Kano model 설명에서 항상 나오는 자동차를 예시로 설명하는 게 더 이해가 쉬울 것 같아 예시를 바꾸어 봤습니다. 대략적인 개념 위주로만 설명을 하는데도 어려움이 많았습니다. 그러나 세부 알고리즘을 하나씩 공부하면 이 논문처럼 재밌는 논문이 없을 것입니다. 자연어 처리와 SHAP value를 하니까 Kano categorization이 가능하다는 획기적인 연구였고, 앞으로의 제 연구에 큰 도움이 될 것 같습니다.
Reference
Joung, J., & Kim, H. M. (2021). Explainable neural network-based approach to Kano categorisation of product features from online reviews. International Journal of Production Research, 1–21. https://doi.org/10.1080/00207543.2021.2000656
Lee, Y. C., & Huang, S. Y. (2009). A new fuzzy concept approach for Kano’s model. Expert Systems with Applications, 36(3), 4479-4484.
Groves, R. M. (2006). Nonresponse rates and nonresponse bias in household surveys. Public opinion quarterly, 70(5), 646-675.
'SSR (SeungHyun Science Review)' 카테고리의 다른 글
| 복잡함보다는 간단한 모델을 쓰라.. 하지만 어떻게? (0) | 2022.10.18 |
|---|---|
| 데이터를 통해 친환경적 제품을 디자인하라 (0) | 2022.06.10 |
| 적정한 삶 균형 잡힌 삶이 역량인 21세기 – Part 2 by 김경일 교수 (0) | 2022.04.17 |
| 적정한 삶 균형 잡힌 삶이 역량인 21세기 – Part 1 by 김경일 교수 (1) | 2022.04.11 |
| 고객을 예측하고 싶다면 그의 관계에 집중하라 (0) | 2022.03.11 |




댓글